
This Pandas exercise project will help Python developers to learn and practice pandas. Pandas is an open-source, BSD-licensed Python library. Pandas is a handy and useful data-structure tool for analyzing large and complex data.
Practice DataFrame, Data Selection, Group-By, Series, Sorting, Searching, statistics. Practice Data analysis using Pandas.
In this exercise, we are using Automobile Dataset for data analysis. This Dataset has different characteristics of an auto such as body-style, wheel-base, engine-type, price, mileage, horsepower, etc.
Also Read:
- Pandas DataFrame
- Also, Solve Python Exercises: 29 topic-wise exercises with over 800+ coding questions
What included in this Pandas exercise?
- It contains 10 questions. The solution is provided for each question.
- Each question includes a specific Pandas topic you need to learn.
When you complete each question, you get more familiar with data analysis using pandas.
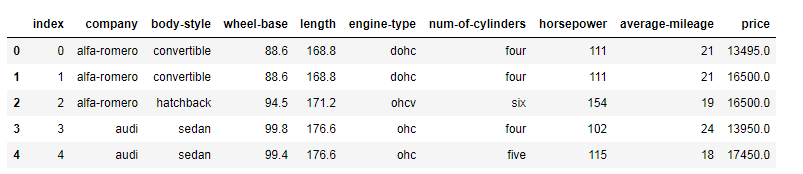
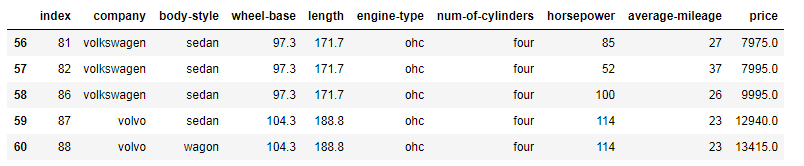
Exercise 1: From the given dataset print the first and last five rows
Expected Output:
Show Solution
Print first five rows
Print last five rows
Exercise 2: Clean the dataset and update the CSV file
Replace all column values which contain ?, n.a, or NaN.
Show Solution
Exercise 3: Find the most expensive car company name
Print most expensive car’s company name and price.
Expected Output:
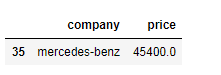
Show Solution
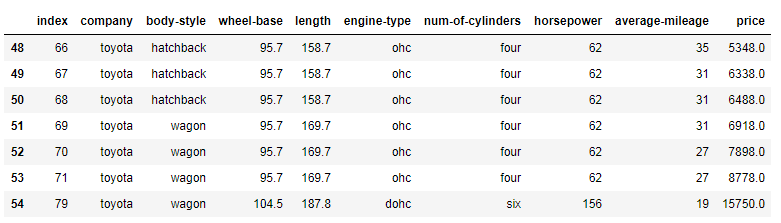
Exercise 4: Print All Toyota Cars details
Expected Output:
Show Solution
Exercise 5: Count total cars per company
Expected Outcome:
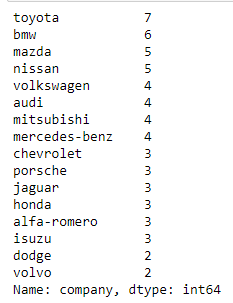
Show Solution
Exercise 6: Find each company’s Higesht price car
Expected Outcome:
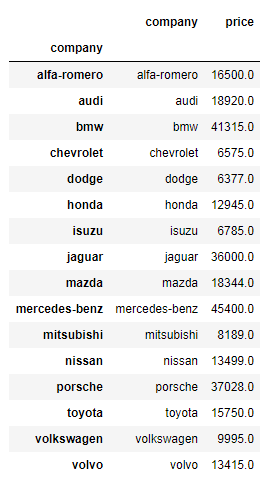
Show Solution
Exercise 7: Find the average mileage of each car making company
Expected Output:
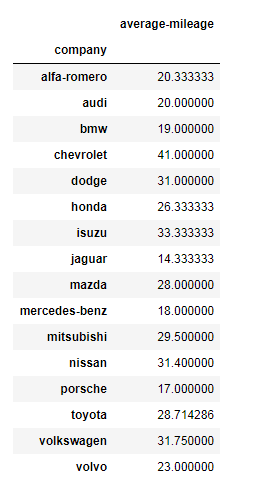
Show Solution
Exercise 8: Sort all cars by Price column
Expected Output:
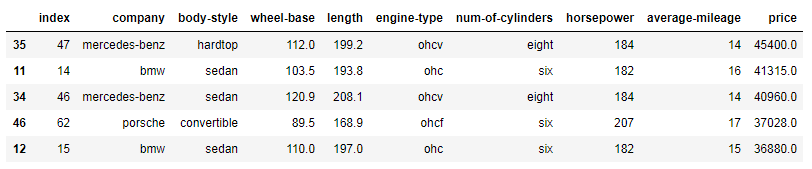
Show Solution
Exercise 9: Concatenate two data frames using the following conditions
Create two data frames using the following two dictionaries.
GermanCars = {'Company': ['Ford', 'Mercedes', 'BMV', 'Audi'], 'Price': [23845, 171995, 135925 , 71400]}
japaneseCars = {'Company': ['Toyota', 'Honda', 'Nissan', 'Mitsubishi '], 'Price': [29995, 23600, 61500 , 58900]}Code language: Python (python)Expected Output:
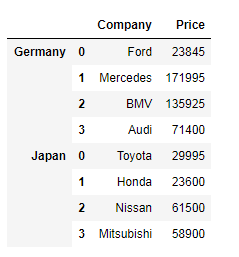
Show Solution
Exercise 10: Merge two data frames using the following condition
Create two data frames using the following two Dicts, Merge two data frames, and append the second data frame as a new column to the first data frame.
Car_Price = {'Company': ['Toyota', 'Honda', 'BMV', 'Audi'], 'Price': [23845, 17995, 135925 , 71400]}
car_Horsepower = {'Company': ['Toyota', 'Honda', 'BMV', 'Audi'], 'horsepower': [141, 80, 182 , 160]}Code language: Python (python)Expected Output:
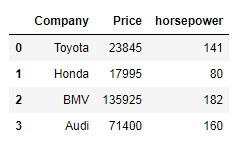
For Exercise 6 in Pandas Exercise, I think the right code is
priceDf = car_Manufacturers[[‘company’,’price’]].max()
instead of
priceDf = car_Manufacturers[‘company’,’price’].max()
Regards
Thank you for such a practice Questions .
Thank you. i know how ta improve now
Hi. Please, in which article can I learn indications about dataframe subsetting, in order to solve exercise n.3?
This was very helpful as i had a massive Deutch_auto.csv and practised with you excerses . Thanks Vishal
couldnt run dictionary one which is to be merge , pls give complete code to run
helped me with learning pandas …thanks bro,looking forward for more excercises
Excellent Tutorial!
4:
car_t=dataset.loc[dataset["company"]=="toyota"]car_t
Correct Approach you have for the pandas dataset separation.
when I try to use the mean() function, it gives the following error, what do i do ?
Could not convert alfa-romeroalfa-romeroalfa-romero to numeric
I have a question could anyone please help me:
How to do this Generate descriptive statistics for the budget of all the movies.
I dont know what code to use
Thankyou Vishal,
These are really helpful.
You’re welcome, Neethu.
Your Python Basics is really amazing. It helped me to learn Python in a well structured way. Hatts off to you bro. Keep up your of upskilling people.
I just had a suggestion whether is it possible for you to write articles on Statistics and Advance Statistics.
Exercises are good but waay too easy… please post some more exercises with increased difficulty. Thanks 🙂
Sir I want more to practice please provide more question
Nicely explained set of practice problems. Thank you.
great boosts up, thanks for the exercises,
You’re welcome, Chari Manepalli.
these exercises are very helpful thanks for your work. I will definitely look for other exercises too. I you are healthy. Lots of love.
Thanks for sharing this! It was super helpful for me to get the basics of pandas! Keep up the share <3
Hi Vishal, this is a good exercise. Thanks for providing this. However, I couldn’t execute exercise 4 with the given code.
Very excellent explanation
Thank you my friend
Super! Ultra! Great! Python Tutorial!
Thank you, Dohyun Jung.
Thank you very much! Super helpful at the first steps with pandas.
thanks alot, it really helps me out to exercise
You’re welcome, Amanjot.
for question 7:
About Question 6: Find each company’s Higesht price car
This solution code will return max value of all the columns that we include to be printed. So, for example, if I add wheel-base column, then the wheel-base value corresponding to the mercedes-benz company will be 120.9 instead of the 112 which corresponds to the row with max price 45400.
Any way to do this?
Good practice for me. Thank you.
It was helpful, thanks!
You’re welcome, Sara.
Wow.
This exercise helped me a lot in reinforcing the concepts.
Found no issues with this exercise.It is great.
Just need more such exercises to practice.
Thank you, Janesh.
Exercise 2 could be better. There’s no null values in the data to begin with.
suggestions to fix Dingus Bingus’s issue:
i) change Exercise 2 wording from:
Replace all column values which contain ?, n.a, or NaN.
to read:
Replace all column values which contain ? and n.a, with NaN.
ii) In MS-Excel:
a) open the csv file
b) insert “?” into cells M24, M25 and M49; then
c) save the changed csv file
Reference:
https://pandas.pydata.org/docs/reference/api/pandas.read_csv.html
(Students may also consider modifying the csv file to test their understanding about how various read_csv parameters work in practice)
Nice exercise please add more such exercises
Question 3.
df=df.groupby(["company"]).sum().sort_values("price", ascending=False) dfcould you provide the link to the data please, preferably in CSV format it would be a real help so that we work with the real data, otherwise great job overall thank you.
Hey Noel Danton, Please download this Automobile Data Set
This exercise is really helpful it helps in reminding and and working with all the functions at
once. i hope you will add more no of exercise in the practice series.
can you please add isnull functionality with data sets ?
for question 4:
Great content 🙂
hi where I will get tutorial on pandas library for beginners with explanation.
Hey Sonal you can read pandas documentation
I learned your pythonmysql, it was good. could you do a tutorial on pandas
Thank you for your suggestions, Jenish dev
Hi Vishal, is there any possibility we can practice online with this data. Thank you very much
Hey Manuel Juarez, unfortunately, we don’t have this feature right now. we are planning to add the interactive exercises in coming months
Very Very useful excercises sir. Please add few more questions around the same lines of pandas and datafram. You can raise the complexity level as well. please provide similar excercises on EDA(Binning, Missing Values, Outlier treatment etc.)
May God Bless you.
Hey Girish, I appreciate your kind words, thank you. And, Yes I will add more such exercises with complex problems.
Hii, this exercise is really very helpful while learning pandas.
I don’t understand solution of question 3.
Can u please explain the solution of question no. 3 ?
This exercise is very helpful in practising Pandas.
Please add some more datasets and exercises.
Thank you, Vishnu Konjeti. yes sure I will add new datasets and exercises