This article shows how to convert a CSV (Comma-separated values)file into a pandas DataFrame. It covers reading different types of CSV files like with/without column header, row index, etc., and all the customizations that need to apply to transform it into the required DataFrame.
In Data Science and business analysis fields, we need to deal with massive data. Most of the time, the data is stored in one or more CSV files, which we need to analyze. Such files can be converted into the Pandas DataFrame to process it efficiently.
Table of contents
- How to Read CSV and create DataFrame in Pandas
- Read CSV with a column header
- Read CSV without a column header
- Read CSV with duplicate columns
- Read CSV with row label
- Read CSV with a multi-index row label
- Read CSV with defined columns and rows
- Read CSV by skipping rows
- Read CSV with Boolean column
- Read CSV with NA values
- Read CSV by changing column data types
- Read CSV with Unicode data
- Improve performance while creating DataFrame from CSV
How to Read CSV and create DataFrame in Pandas
To read the CSV file in Python we need to use pandas.read_csv() function. It read the CSV file and creates the DataFrame. We need to import the pandas library as shown in the below example.
Example
Let’s see how to read the Automobile.csv file and create a DataFrame and perform some basic operations on it.
To get more details on the useful functions of DataFrame for data analysis, you can refer to the article Pandas DataFrame.
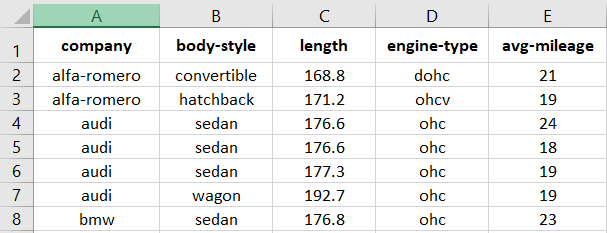
Output
company body-style length engine mileage sunroof
0 alfa-romero convertible 168.8 dohc 21 No
1 alfa-romero hatchback 171.2 dohc 19 No
.. … … … … … …
58 volvo sedan 188.8 ohc 23 No
59 volvo wagon 188.8 ohc 23 No
[60 rows x 6 columns]Get metadata of the CSV
DataFrame.info() function is used to get the metadata of the DataFrame.
Output
RangeIndex: 60 entries, 0 to 59 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 company 60 non-null object 1 body-style 60 non-null object 2 length 60 non-null float64 3 engine 60 non-null object 4 mileage 60 non-null int64 5 sunroof 60 non-null object dtypes: float64(1), int64(1), object(4) memory usage: 2.9+ KB
Select rows from CSV
We can select top ‘n’ or bottom ‘n’ rows from a DataFrame using DataFrame.head() and DataFrame.tail() functions respectively.
Output
Top rows from DataFrame:
company body-style length engine mileage sunroof
0 alfa-romero convertible 168.8 dohc 21 No
1 alfa-romero hatchback 171.2 dohc 19 No
Bottom rows from DataFrame:
company body-style length engine mileage sunroof
58 volvo sedan 188.8 ohc 23 No
59 volvo wagon 188.8 ohc 23 No
Get element from DataFrame
If we need to select a particular element from DataFrame using row and column label then we can do that using DataFrame.at() function.
Read CSV with a column header
While analyzing the data from CSV files, we need to handle both types of files, which may or may not contain headers.
Using the header parameter of DataFrame.read_csv(), we can specify the row number which contains column headers. By default, it considers the first row as a header, i.e., header=0.
For example, if we give header=3, then the third row in the file is considered the column header, and all the rows before that are ignored i.e. row 0 to 2 as shown in the below example.
If we pass the column labels explicitly, then the behavior of this parameter is header=None.
Output
audi sedan 176.6 ohc 24 Yes 0 audi sedan 176.6 None 18.0 Yes 1 audi sedan 177.3 ohc 19.0 Yes .. ... ... ... ... ... ... 58 volvo sedan 188.8 ohc 23.0 No 59 volvo wagon 188.8 ohc 23.0 No [60 rows x 6 columns]
Read CSV with a multi-index column header
As explained in the above section, the header parameter of DataFrame.read_csv() is used to specify the header. When we have more than one header row, also called “multi-index headers“, we can use the same parameter. We can specify row numbers of the headers as a list of integers to the header parameter.
In the below example, we have the first two rows as headers.
Output
company body-style length engine mileage sunroof
Name Description size type average is Availabe?
0 alfa-romero convertible 168.8 dohc 21.0 No
1 alfa-romero hatchback 171.2 NaN 19.0 No
2 audi sedan 176.6 ohc 24.0 Yes
.. ... ... ... ... ... ...
61 volvo sedan 188.8 ohc 23.0 No
62 volvo wagon 188.8 ohc 23.0 No
[63 rows x 6 columns]
Read CSV without a column header
In case we need to read CSV, which does not have a column header and we want to explicitly specify the column labels, we can use the parameter name of DataFrame.read_csv().
It takes a list of column names as input. By default, it’s None. Duplicate column names are not allowed.
Example
Let’s see how to specify the column names to the DataFrame from CSV.
Output:
Index(['company_name', 'type', 'len', 'etype', 'milage', 'sunroof'], dtype='object')
Default column header
There could be a case that while reading a CSV that does not contain a column header and if it has so many columns, and we cannot explicitly specify the column labels.
In such a case, we want to give the default column labels we can use the prefix parameter of DataFrame.read_csv(). It generates the column labels by appending the prefix and column number.
For example, if we specify the prefix="Col_" then the default column names of the resultant DataFrame will be Col_1, Col_2, Col_3,…, Col_n.
Note: We need to set header=None with prefix parameter.
Output
Index(['Col_0', 'Col_1', 'Col_2', 'Col_3', 'Col_4', 'Col_5'], dtype='object')
Read CSV with duplicate columns
When we have duplicate column labels in the CSV file and want all those columns into the resultant DataFrame, we need to use the parameter mangle_dupe_cols of the read_csv(). It is a boolean flag.
- If
mangle_dupe_cols=True, which is the default case, manages the duplicate columns by renaming their labels. It renames the column labels by appending a suffix to them.
For example, if there are multiple columns with the label “company,” then the resultant DataFrame column names are “company”, “company.1”, “company.2”, and so on. - If
mangle_dupe_cols=False, it will overwrite the data in the duplicate column.
Example
The below example shows the default behavior when we have the “company” column duplicated.
Output
Index(['company', 'body-style', 'length', 'engine', 'mileage', 'sunroof', 'company.1'], dtype='object')
Read CSV with row label
The CSV file has row numbers that are used to identify the row. If we want the same behavior in the resultant DataFrame we can use the parameter index_col of read_csv().
By default, it gives a range of integers as row index i.e. 0, 1, 2,…n a row label. But if we already have a column in the CSV which needs to be used as a row index then we can specify its name or index position in the index_col parameter.
Example
In the below example, we want to use the company name as a row index.
Output
body-style length engine mileage sunroof company alfa-romero convertible 168.8 dohc 21.0 No alfa-romero hatchback 171.2 NaN 19.0 No audi sedan 176.6 ohc 24.0 Yes ... ... ... ... ... ... volvo sedan 188.8 ohc 23.0 No volvo wagon 188.8 ohc 23.0 No [63 rows x 5 columns]
Read CSV with a multi-index row label
As explained in the above section, Row label is specified using the index_col parameter of DataFrame.read_csv(). We can give a list of column names or positions in the index_col parameter in the multi-index case.
Example
In the below example, we have the first two columns, ‘company‘ and ‘body–style‘ as row index.
Output
length engine mileage sunroof
company body-style
alfa-romero convertible 168.8 dohc 21.0 No
hatchback 171.2 NaN 19.0 No
audi sedan 176.6 ohc 24.0 Yes
... ... ... ... ...
volvo sedan 188.8 ohc 23.0 No
wagon 188.8 ohc 23.0 No
[63 rows x 4 columns]
Read CSV with defined columns and rows
In Data Science and Machine Learning field, massive data is generated, which needs to be analyzed. But, many times, we get redundant data. To filter such data, we use usecols and nrows parameters of DataFrame.read_csv().
usecols: As the name suggests, it is used to specify the list of column names to be included in the resultant DataFrame. It takes a list or callable function as an input, which is used to filter the columns.nrows: It is used to specify the number of rows to read. It takes integer input. By default, it is None which meansDataFrame.read_csv()reads the whole file.
Example
Both the parameters are used to read the subset of a large file. In the below example, we created the DataFrame with 2 columns and 10 rows out of 60 rows and 6 columns.
Output:
company body-style 0 alfa-romero convertible 1 alfa-romero hatchback 2 audi sedan .. ... ... 7 bmw sedan 8 NaN NaN 9 bmw sedan [10 rows x 2 columns]
Read CSV by skipping rows
While converting the large file into the DataFrame, if we need to skip some rows, then skiprows parameter of DataFrame.read_csv() is used.
It takes the following inputs:
- integer: number of rows to skip from the start.
- list of integers: line numbers to skip starting at 0.
- callable function: Callable function gets evaluated for each row. If it returns True, then the row is skipped.
Example
In the below example, we declared a lambda function that returns True for an odd number of the row. So we skip every alternate even row.
Output
company body-style length engine mileage sunroof 0 alfa-romero hatchback 171.2 NaN 19.0 No 1 audi sedan 176.6 None 18.0 Yes .. ... ... ... ... ... ... 29 volkswagen sedan 171.7 ohc 26.0 Yes 30 volvo sedan 188.8 ohc 23.0 No [31 rows x 6 columns]
Read CSV with Boolean column
In the Data Science field, it is a very common case that we do not get data in the expected format. And it mostly happens with Boolean values. Commonly considered boolean values are TRUE, FALSE, True, or, False. But, if we need to recognize other values as a boolean then we can specify them using true_values and false_values parameters of DataFrame.read_csv().
Here, we have data with the column “sunroof“, which indicates if the car has a feature of a sunroof or not. It has the values “Yes” and “No” for each car. Suppose for the simplification of our operations, and we want to treat it as boolean values; then we can achieve this by using true_values=["Yes"], false_values=["No"] as shown in the below example.
Output:
Before :
sunroof
0 No
1 No
2 Yes
.. ...
61 No
62 No
[63 rows x 1 columns]
After :
sunroof
0 False
1 False
2 True
.. ...
61 False
62 False
[63 rows x 1 columns]
Read CSV with NA values
Data that need to be analyzed either contains missing values or is not available for some columns. Before applying any algorithm on such data, it needs to be clean. In this section, we discuss the parameters useful for data cleaning, i.e., handling NA values.
Following parameters are used together for the NA data handling:
na_values: It is used to specify the strings which should be considered as NA values. It takes a string, python list, or dict as an input. The default value is None.keep_default_na: If we have missing values or garbage values in the CSV file that we need to replace withNaN, this boolean flag is used. The default value is True. It will replace the default NA values and values mentioned in the parameterna_valueswithNaNin the resultant DataFrame.na_filter: If this parameter’s value is False, then the parametersna_valuesandkeep_default_naare ignored.
Note: If it is set to False, it improves the performance by ignoring parsing of garbage and missing data.
Example
Let’s see how we can handle value “Not-Avail” by converting it into NaN.
Output:
Before cleaning:
company body-style length engine mileage sunroof
0 alfa-romero convertible 168.8 dohc 21 No
1 Not-Avail Not-Avail Not-Avail Not-Avail Not-Avail Not-Avail
2 alfa-romero hatchback 171.2 NaN 19 No
3 NaN NaN NaN NaN NaN NaN
4 audi sedan 176.6 ohc 24 Yes
After cleaning:
company body-style length engine mileage sunroof
0 alfa-romero convertible 168.8 dohc 21.0 No
1 NaN NaN NaN NaN NaN NaN
2 alfa-romero hatchback 171.2 NaN 19.0 No
3 NaN NaN NaN NaN NaN NaN
4 audi sedan 176.6 ohc 24.0 Yes
Read CSV by changing column data types
As you know, data is gathered from different sources. They all are of different formats and types which we need to combine and analyze. In such cases, we need to change the data types to keep them uniform.
There are multiple ways to do it. The most widely used parameters of DataFrame.read_csv() is dtype:
- If we want to convert all the data into a single data type then we can use it as
dtype=data_type - If we want to change the data type of each column separately then we need to pass a dict as
dtype={'col_name': 'new_dt'}. Where the key of the dict is column name and value is the data type.
Example
In the below example, we are changing the column “mileage” from int64 to float64.
Output:
Data type before : mileage int64 Data type after : mileage float64
Read CSV with Unicode data
As datasets are gathered from various sources to analyze it. For example, we want to analyze the world’s population. For that, we gather the data from different countries it is highly likely that the data contains characters encoded country-wise into the different formats.
If we try to read such CSV file with encoded characters using DataFrame.read_csv() then it gives the error like:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe4 in position 2: invalid continuation byteCode language: Python (python)To read such files encoding parameter is used. In the following example, the EncodedData.csv file contains Latin characters that are encoded with the “latin-1” format.
Output:
Names 0 Träumen 1 Grüße
Improve performance while creating DataFrame from CSV
In Data Analytics and Artificial Intelligence, we work on data from kilobytes to terabytes and even more. In both cases, from small to enormous datasets, performance is the primary concern.
Following parameters of DataFrame.read_csv() is concerned with performance improvement while creating DataFrame from the CSV file.
low_memory: By default, this flag is True. It processes the data from CSV into chunks and converts all the chunks into the DataFrame. It results in low memory usage.memory_map: By default, it is false. It reads the data into memory and accesses it from there. It does not read the data from the disk, which avoids the IO operation. So when we are dealing with small data or have no concern with RAM, we can load the CSV file into the memory and avoid IO reads.
Leave a Reply