This article shows how to convert a Python dictionary to pandas DataFrame. It covers the creating DataFrame from all types of dictionaries using the DataFrame constructor and from_dict() method.
And at the end of this article, we summarize the usage of both ways with the comparison. So stay tuned…
Python dictionary is the data structure that stores the data in key-value pairs. By converting data from dictionary format to DataFrame will make it very competent for analysis by using functions of DataFrame.
There are multiple ways to convert Python dictionary object into Pandas DataFrame. Majorly used ways are,
- DataFrame constructor
from_dict()
Table of contents
- Create DataFrame from dict using constructor
- DataFrame from dict with required columns only
- DataFrame from dict with user-defined indexes
- DataFrame from dict by changing the column data type
- DataFrame from dict with a single value
- DataFrame from dict with key and value as a column
- Create DataFrame from list of dict
- The from_dict() function
- DataFrame from dict with dict keys as a row
- DataFrame from dict where values are variable-length lists
- DataFrame from dict nested dict
- DataFrame constructor vs from_dict()
Create DataFrame from dict using constructor
DataFrame constructor can be used to create DataFrame from different data structures in python like dict, list, set, tuple, and ndarray.
In the below example, we create a DataFrame object using dictionary objects contain student data.
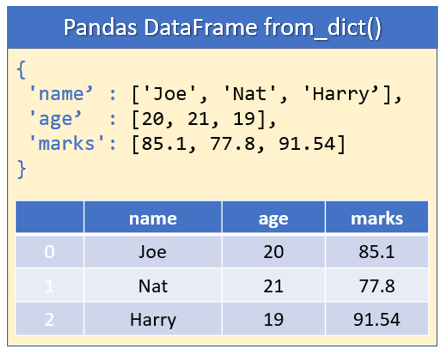
When you convert a dict to DataFrame by default, all the keys of the dict object becomes columns, and the range of numbers 0, 1, 2,…,n is assigned as a row index.
Output:
{'name': ['Joe', 'Nat', 'Harry'], 'age': [20, 21, 19], 'marks': [85.1, 77.8, 91.54]}
name age marks
0 Joe 20 85.10
1 Nat 21 77.80
2 Harry 19 91.54
DataFrame from dict with required columns only
While converting the whole dict to DataFrame, we may need only some of the columns to be included in the resulting DataFrame.
We can select only required columns by passing list column labels to columns=['col1', 'col2'] parameter in the constructor.
Example
In the case of student DataFrame for analyzing the annual score, we need only “student name” and “marks” whereas the “age” column is not required. We can select only required columns, as shown in the below example.
Output:
{'name': ['Joe', 'Nat', 'Harry'], 'age': [20, 21, 19], 'marks': [85.1, 77.8, 91.54]}
name marks
0 Joe 85.10
1 Nat 77.80
2 Harry 91.54
DataFrame from dict with user-defined indexes
In pandas DataFrame, each row has an index that is used to identify each row. In some cases, we need to provide a customized index for each row. We can do that while creating the DataFrame from dict using the index parameter of the DataFrame constructor.
The default index is a range of integers starting from 0 to a number of rows. We can pass a list of the row indexes as index=['index1','index2'] to the dataFrame constructor.
Example
In the below example, we have given a customer index for each student, making it more readable and easy to access the row using it.
Output:
{'name': ['Joe', 'Nat', 'Harry'], 'age': [20, 21, 19], 'marks': [85.1, 77.8, 91.54]}
name age marks
stud1 Joe 20 85.10
stud2 Nat 21 77.80
stud3 Harry 19 91.54
DataFrame from dict by changing the column data type
By default, while creating a DataFrame from dict using constructor, it keeps the original data type of the values in dict. But, if we need to change the data type of the data in the resulting DataFrame, we can use the dtype parameter in the constructor.
Only one data type is allowed to specify as dtype='data_type' which will be applicable for all the data in the resultant DataFrame. If we do not force such a data type, it internally infers from the Data.
Note: It changes the data type only if it is compatible with the new data type. Otherwise, it keeps the original data type.
Example
As you can see below example, we are trying to change the data type to float64 for all the columns. But, it changes the data type of “age” and “marks” columns only to float64 even though the “marks” column type was “object“. But, the “name” column type is not changed because string values in that column cannot be converted to float64.
Output:
DataFrame with inferred data type :
name object
age int64
marks object
dtype: object
DataFrame with changed data type :
name object
age float64
marks float64
dtype: object
name age marks
0 Joe 20.0 85.00
1 Nat 21.0 77.00
2 Harry 19.0 91.54
DataFrame from dict with a single value
If we have a dict with only single values for each key and need to convert such dict to the DataFrame, we can use the DataFrame constructor.
In such a case, it converts the dict to DataFrame as we have seen before, like keys of the dict will be column labels and values will be the column data. But, we must provide the index parameter to give the row index. Else it throws an error,
ValueError: If using all scalar values, you must pass an index
Example
In the below example, we have provided the customized index=['stud1'] to the DataFrame.
Output:
{'name': 'Smith', 'age': 22, 'marks': 88.9}
name age marks
stud1 Smith 22 88.9
DataFrame from dict with key and value as a column
Suppose we have a dictionary object where the key is the student’s name, and the value is the student’s marks. And we want the keys in one column and all the values in another column of the DataFrame.
For that, rather than passing a whole dict object, we need to pass each key-value pair in the dictionary to the DataFrame constructor to create a new DataFrame.
We can get the entry of key-value pair using dict.items() and pass that function to the constructor.
Example
As shown in the below example, we need to pass an entry of key-value to the constructor and give column labels using columns parameter.
Output:
{'Joe': 85.1, 'Nat': 75.83, 'Harry': 69.7}
name marks
0 Joe 85.10
1 Nat 75.83
2 Harry 69.70
Create DataFrame from list of dict
For the sake of our understanding, consider the case where each school stores data of students into the dictionary data structure. Each school store different information about students. Like, some school stores student’s hobby whereas some school only stores academic information. If we want to analyze data of all the students from the city, we need to gather all this information into the DataFrame.
To convert such a list of dict from different schools can be converted to a single DataFrame using either DataFrame.from_dict() function or DataFrame constructor.
By default, keys of all the different dictionary objects are converted into columns of resultant DataFrame. It handles the missing keys by adding NaN where the values for the column are missing.
Example
Let’s see how we can use a constructor to create DataFrame from different dictionary objects.
Output:
[{'name': 'Joe', 'age': 20, 'marks': '85.58', 'hobby': 'smimming'}, {'name': 'Nat', 'age': 21, 'marks': '77.21'}, {'name': 'Harry', 'age': 19, 'marks': '91.54'}]
name age marks hobby
0 Joe 20 85.58 smimming
1 Nat 21 77.21 NaN
2 Harry 19 91.54 NaN
The from_dict() function
This is another way of creating DataFrame from a Python dictionary using DataFrame.from_dict() method.
Note: This method is useful for the cases when you need to transpose the DataFrame i.e. when we need the keys in the dictionary object as rows in the resultant DataFrame. In all the other cases DataFrame constructor should be preferred.
DataFrame.from_dict(data, orient='columns', dtype=None, columns=None)Code language: Python (python)data: It takesdict,list,set,ndarray,Iterable, orDataFrameas input. An empty DataFrame will be created if it is not provided. The resultant column order follows the insertion order.orient: (Optional) If the keys of thedictshould be the rows of the DataFrame, then setorient = indexelse set it tocolumn(Default) if the keys should be columns of the resultant DataFrame.dtype: (Optional) data type to force on resulting DataFrame. Only a single data type is allowed. If not given, then it’s inferred from the data.columns: (Optional) Only be used in case oforient="index"to specify column labels in the resulting DataFrame. Default column labels are range of integer i.e. 0,1,2…n. Note: If we use thecolumnsparameter withorient='columns'it throws anValueError: cannot use columns parameter with orient='columns'
DataFrame from dict with dict keys as a row
It is used to transpose the DataFrame, i.e., when keys in the dictionary should be the rows in the resultant DataFrame. We can change the orientation of the DataFrame using a parameter orient="index" in DataFrame.from_dict().
Example
In the below example, keys “name“, “age“, and “marks” becomes row indexes in the DataFrame, and values are added in respective rows. New column labels are provided using columns parameter.
Output:
{'name': ['Joe', 'Nat', 'Harry'], 'age': [20, 21, 19], 'marks': [85.1, 77.8, 91.54]}
stud1 stud2 stud3
name Joe Nat Harry
age 20 21 19
marks 85.1 77.8 91.54
DataFrame from dict where values are variable-length lists
It is a widespread use case in the IT industry where data is stored in the dictionary with different values against each key.
If such a dictionary object needs to be converted into the DataFrame such that keys and values will be added as columns in DataFrame. Then it can be done using chaining of DataFrame.from_dict(), stack(), and reset_index() functions.
Example
Here, we have dict with values are of different sizes and still we need to add all the key-values into a DataFrame.
Output:
{'Grade A': ['Joe', 'Harry'], 'Grade B': ['Nat']}
level_0 0
0 Grade A Joe
1 Grade A Harry
0 Grade B Nat
DataFrame from dict nested dict
In this section, we cover the complex structure of the dictionary object where we have a hierarchical structure of the dictionary i.e. one dictionary object into another dictionary object.
In the below example, we have a student dictionary object where student data categorized by their grades and further divided as per their class. Such a dictionary object is converted into the multi-index DataFrame using DataFrame.from_dict() by iterating over each key and its values and parameter orient='index'.
Output:
{'Grade A': {'Class A': {'name': 'Joe', 'marks': 91.56}, 'Class B': {'name': 'Harry', 'marks': 87.9}}, 'Grade B': {'Class A': {'name': 'Sam', 'marks': 70}, 'Class B': {'name': 'Alan', 'marks': 65.48}}}
name marks
Grade A Class A Joe 91.56
Class B Harry 87.90
Grade B Class A Sam 70.00
Class B Alan 65.48
DataFrame constructor vs from_dict()
The below table summarizes all the cases of converting dict to the DataFrame that we have already discussed in this article. It shows the comparison of using the DataFrame constructor and DataFrame.from_dict() method.
It will help you to choose the correct function for converting the dict to the DataFrame.
| Use Case | DataFrame constructor | from_dict() method |
|---|---|---|
| Custom column names | Yes | No |
| custom index | Yes | No |
| dict with a single value | Yes | No |
| list of dict | Yes | Yes |
| handle missing keys | Yes | Yes |
| keys and values as columns | Yes | Yes |
| change datatype | Yes | Yes |
| Orient=column(Keys as columns) | Yes | Yes |
| Orient=index(Keys as rows) | No | Yes |
| Multi-index DataFrame | No | Yes |
Leave a Reply